前の記事
関数2.0(Formulas 2.0)を徹底解説
最近の更新内容
2024.05.19 追加
-
today()mean()median()の3つの関数を追加しました。Notion 公式アップデート情報はこちら → Notion 2.39: 基本に立ち戻る
今回の記事では、2023 年 9 月にアップデートされた Notion の関数機能「関数 2.0(Formula 2.0)」について解説します。アップデート前の「関数 1.0(Formula 1.0)」からの変更点、新しく追加された機能や関数、「関数 2.0(Formula 2.0)」を使ったユースケースについて詳しく紹介しています。
💡
2023年12月に 「関数」プロパティの名称が「数式」プロパティに変更になりました。この記事では、以前の名称である「関数」プロパティのまま解説を行っています。

1. 関数 2.0(Formula 2.0)の新機能
関数 2.0 の新機能や 関数 1.0 からの変更点の概要は以下です。
-
prop("プロパティ名")の書き方が変わった - エディタが新しくなり使いやすくなった
- 改行・インデント・コメントが使えるようになった
- 新しい関数が追加された
- 変数が使えるようになった
- ドット記法で関数が書けるようになった
- ロールアップなしでリレーション先のデータベースの情報が取得できるようになった
- リスト(配列)操作が可能になった
上記以外にもアップデートはいくつかありますが、わかりやすいものから一つずつ順番に紹介していきます。
prop("プロパティ名")の書き方が変わった
以下のようなデータベースがあるとします。
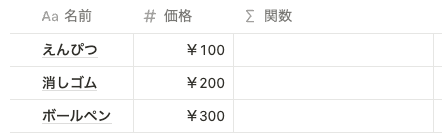
以前までは、関数で 名前 プロパティを指定したい場合は、 prop(”名前”) と指定していました。しかし、関数 2.0 では、以下のように prop がなくなり、プロパティ名を直接指定する形式になりました。プロパティ名は、背景色がグレーになります。
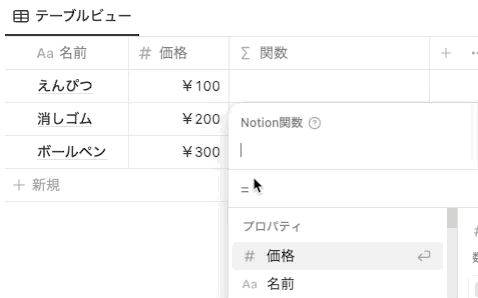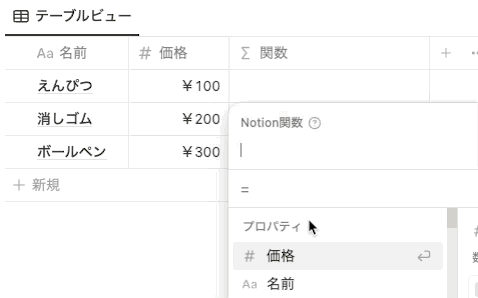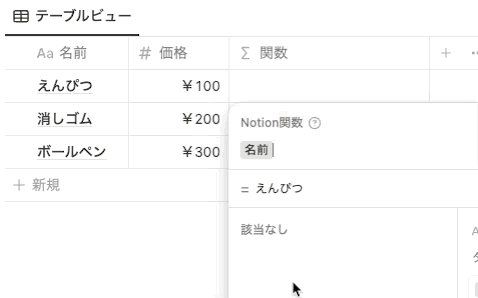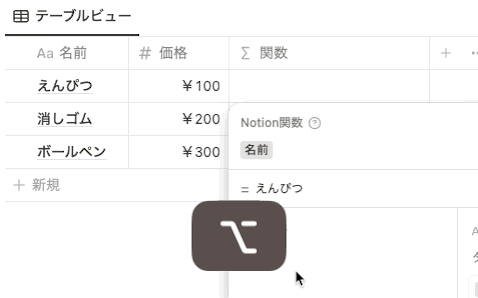
ただし注意点として、ブログの記事などに記載されている関数をコピペで貼り付ける場合は、貼り付け元は以前と同様に prop(”プロパティ名”) の形式で記載されている必要があります。 prop(”プロパティ名”) をペーストすると、自動で新しい形式に変換されます。
※ この記事でもプロパティ名には prop をつけて記載するので、画像で表示される表現との違いにご注意ください。
エディタが新しくなり使いやすくなった
エディタの 機能や UI が新しくなり、非常に使いやすくなりました。新しくなったエディタは以下のような特徴があります。
- 関数の出力結果がリアルタイムに表示される
- エラー箇所がわかりやすく表示される
まず、新しいエディタでは以下のように関数の出力結果がリアルタイムに表示されます。
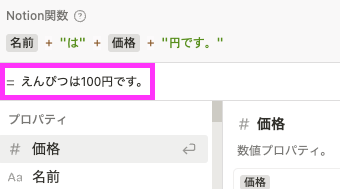
また、関数の内容にエラーがある場合、エラー箇所に赤色の下線が表示されるので、修正箇所がわかりやすくなりました。

改行・インデント・コメントが使えるようになった
新しいエディタでは、改行・インデント・コメントを関数内に追加することができます。例えば以前までの書き方の場合、以下の関数は内容がとても分かりにくいです。

対して 関数 2.0 では、改行やインデント、コメントを追加することで関数の内容が分かりやすくなりました。

改行は Shift + Enter で可能です。
コメントは /* コメント * / のように / **/ でコメントを囲みます。
また、編集画面内でキーボードでカーソル移動したい場合は、 Option/Alt + ↑/↓ で可能です。
新しい関数が追加された
新しい関数がいくつか追加され、できることが増えたり、できたとしても複雑だったことがより簡単な関数でできるようになりました。
-
style():関数の出力結果を色や背景色、太字などで装飾 -
link():関数の出力結果をリンクに変換。Excel のハイバーリンクと同等の機能 -
ifs():Excel の ifs と同等の機能 -
parseDate():文字列を日付に変換 -
dateRange():@2022年9月7日 → 2023年9月7日のような日付範囲を出力 -
week():任意の日付の週番号を返す -
repeat():文字列を任意の回数繰り返して出力 -
upper():文字列を大文字に変換 -
lower():文字列を小文字に変換
これらの関数に関しては、後で詳しく解説します。
変数が使えるようになった
新しく追加された let 、 lets 関数を使うことで変数を扱えるようになりました。例えば、以下の関数では、消費税 10 %( 1.1 )を tax という変数に代入して、100 * tax という部分で 100 * 1.1 という計算を行っていることになります。
let(tax, 1.1, 100 * tax) 上記のようなシンプルな内容であれば let を使用する必要はありませんが、 tax が何回も出てくるような複雑な計算をする場合などに関数をすっきりと書くことができるようになるのでとても便利です。こちらについても後で詳しく解説します。
ドット記法で関数が書けるようになった
例えば、「今日から 10日後」の日付を計算したい場合、今までの書き方であれば dataAdd() を使って以下のように記載する必要がありました。
dateAdd(now(), 10, "days") 今までの書き方の場合、関数の () 内の引数で値や条件を書かなければいけませんでした。対して新しい記述方法のドット記法では、上記と同様の内容を以下のように書き換えることができます。
now().dateAdd(10, "days")新しい記述方法の場合は、今の時刻に対して 10日を足すというように、前から順に見ていけばいいので関数の内容が分かりやすくなります。
もっと複雑な内容で比較してみると、メリットがさらに分かりやすくなります。例えば、「今日から 1 年 6 ヶ月 10 日後」の日付を出力したい場合、今までの書き方であれば以下のようになります。
dateAdd(dateAdd(dateAdd(now(), 10, "days"), 6, "months"), 1, "years")対して、ドット記法であれば以下のようになります。
now().dateAdd( 1, "years" ) /* 1年後 */
.dateAdd( 6, "months") /* 6か月後 */
.dateAdd(10, "days") /* 10日後 */このように、複雑な内容であればあるほど、ドット記法(+コメント)を使うことで関数の意味が分かりやすくなります。現在でも、今までの記述方法は使用することができるので今まで使っていた関数を修正する必要はありませんが、これから作成する関数に関してはドット記法を使用するのがおすすめです。
ロールアップなしでリレーション先のデータベースの情報が取得できるようになった
以前まで、別のデータベースの情報を取得したい場合は、「リレーション → ロールアップ」を行う必要がありました。
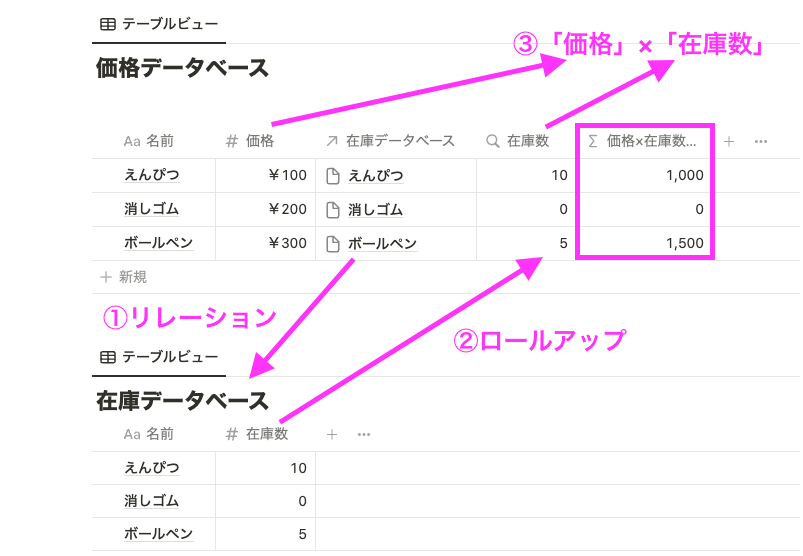
対して、関数 2.0 からは、関数から直接リレーション先のプロパティを参照できるようになりました。つまり、「ロールアップ」(上の画像の「在庫数」プロパティ)を追加する必要がありません。
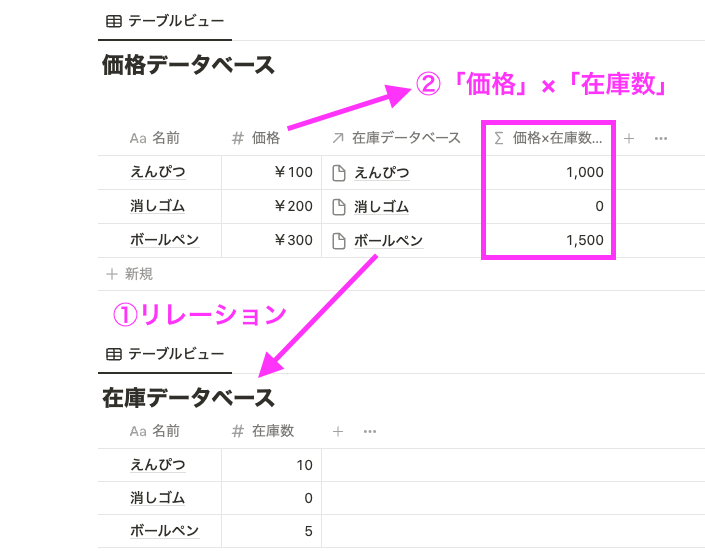
詳細は後で解説しますが、関数は以下のようになっています。 prop(”在庫データベース").map(current.prop("在庫数")).first() の部分で、「在庫データベース」の「在庫数」プロパティの情報を直接(ロールアップなしで)取得しています。
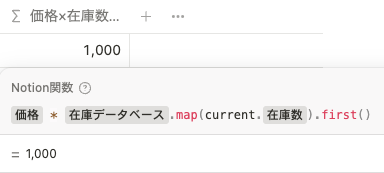
さらにロールアップではできなかったフィルタや並び替えも 関数 2.0 ではできるようになったので、以前よりもさらにできることの幅が広がりました。
リスト(配列)操作が可能になった
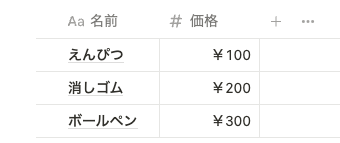
関数 2.0 では、「リスト(配列)操作」が可能になりました。例えば、以下の「価格」ぷろに消費税 10 % を掛けた価格の合計値を関数で出力したい場合を例とします。
こちらも詳細は後で解説しますが、関数は以下のようになっています。

まずは自分のデータベースの「価格プロパティ」の情報を参照できるように自分のデータベースとリレーションします。 prop(”価格データベースとのリレーション").map(current.prop("価格") * 1.1 ) の部分で、
- 100 * 1.1 = 110
- 200 * 1.1 = 220
- 300 * 1.1 = 330
をそれぞれ計算し、最後の .sum() で 110 + 220 + 330 = 660 を計算しています。このようにリスト操作ができるようになったことで、実現できることがとても増えました。リスト操作に関しても、詳細は後で解説します。
✅
リスト操作については動画でも解説しています。ぜひ合わせてチェックしてみてください。
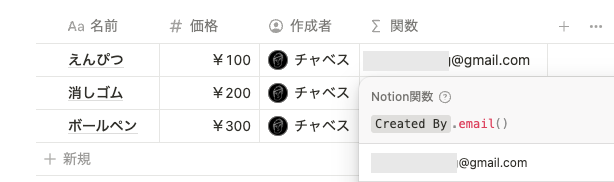
名前やメールアドレスなどのワークスペースレベルの情報を取得できるようになった
以下のようなデータベースで、「作成者」のフルネームやメールアドレスを簡単に取得できるようになりました。
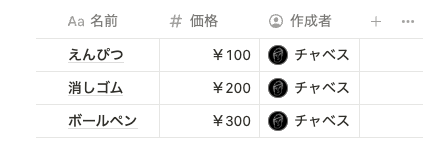
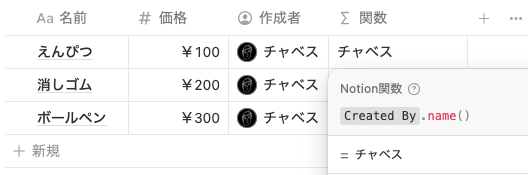
名前は、以下のように name() を使うことで取得できます。
メールアドレスは、以下のように email() を使うことで取得できます。
2. 新しく追加された関数(リスト関連を除く)
ここからは、新しく追加された関数のより詳しい使い方を解説します。ただし、リスト操作(配列操作)に関しては、後でまとめて解説するのでここでは割愛します。
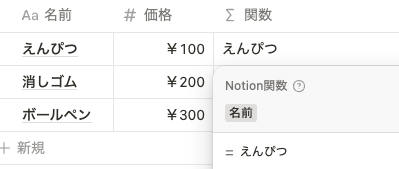
style()
style() は、関数の出力結果を装飾することができます。例えば、何も装飾しない場合は以下のような表示になります。
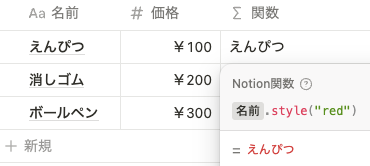
以下のように prop(”名前").style(”red”) とすると、赤色に装飾されます。
さらに、 prop(”名前").style("red", "yellow_background", "b", "u") とすると、背景色、太字、下線が追加されます。
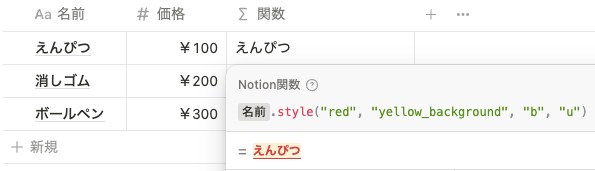
有効な書式設定スタイルには、 "b" (太字)、 "u" (下線)、 "i" (斜体)、 "c" (コード)、 "s" (取り消し線)があります。有効な色には、 "gray" 、 "brown" 、 "orange" 、 "yellow" 、 "green" 、 "blue" 、 "purple" 、 "pink" 、 "red" があります。背景色を設定するには、 "blue_background" のように 有効な色_background の形式で追加することができます。
ちなみに unstyle() という装飾を削除する関数もありますが、使用する場面が少ないことが想定されるので割愛します。使い方は style() と同様です。
link()
今まで、データベースの URL は下記のようにアドレスそのままの形式でしか表示することができませんでした。
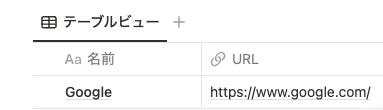
関数 2.0 では、 link() を使うことでエクセルのハイパーリンクのような表示にすることができてリンクがみやすくなります。下記の Google の例では、「関数」プロパティの「Google」というテキストがハイパーリンクになっており、クリックすると Google のページに遷移することができます。
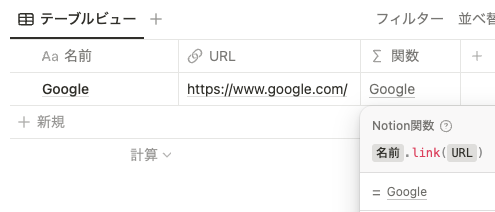
prop(”名前”).link(prop(”URL”)) 先に説明した style() と組み合わせれば、さらに分かりやすい表示にすることができます。
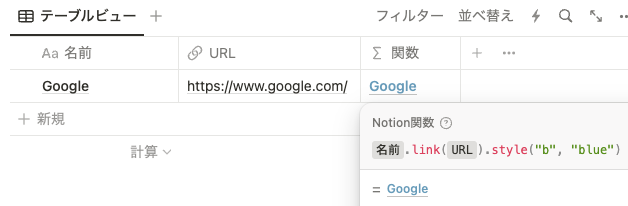
prop("名前").link(prop("URL")).style("b", "blue")ifs()
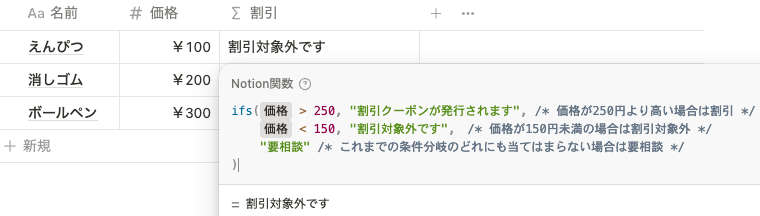
ifs() は エクセルの ifs() と同じような機能を持つ関数です。例えば、 if() を使っていくつかの条件分岐をしたい場合、以下のように少し見づらくなってしまいます。
対して、 ifs() を使うと以下のように条件分岐を分かりやすく記載することができます。最後の”要相談”の部分は、今までの条件分岐のどれにも当てはまらない場合に出力される内容です。また、今回は 3つの条件分岐でしたが、条件分岐はいくつになっても問題ありません。
parseDate()
今まで文字列を日付に変換する場合、 dateAdd や dateSubtract 関数を使ってかなり複雑な関数を書く必要がありました。対して、関数 2.0 では parseDate() を使ってとても簡単に文字列を日付に変換することができます。
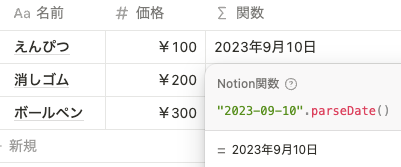
"2023-09-10".parseDate() ただし、日付は ISO8601 という形式に従っている必要があります。例えば、 2023/09/10 という文字列は直接 parseDate() で日付に変換することはできないので、以下のように replaceAll() で / を削除してから parseDate() で変換する必要があります。
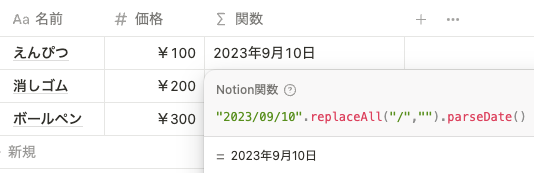
"2023/09/10".replaceAll("/","").parseDate()dateRange()
dateRange() は、以下のように開始日と終了日を指定して日付範囲を出力することができます。
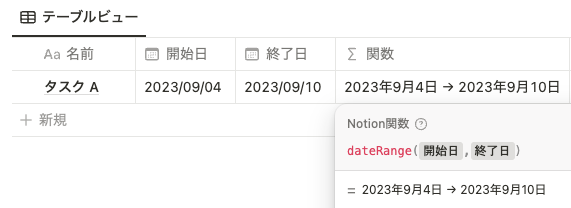
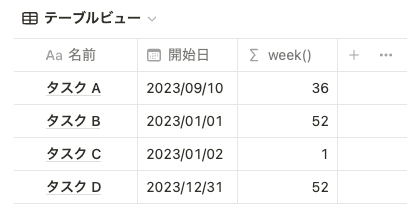
dateRange(prop("開始日"),prop("終了日"))week()
対象の日付の年の ISO週 (1~53)を返します。簡単にいうと、対象の日付がその年の「第何周目か」を出力します。
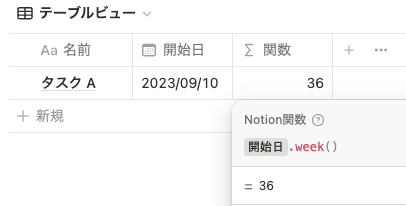
prop("開始日").week() ただし注意点として、日曜始まりではなく月曜始まりです。例えば 2023-01-01 は日曜なので前の年(2022年)の週番号 52 で出力されます。対して、 2023-01-02 は月曜なので 1 と出力されます。
repeat()
repeat() はシンプルな機能で、指定した文字列を指定した回数繰り返します。
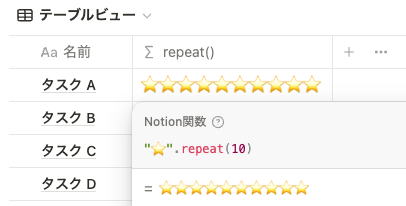
"⭐".repeat(10)upper()・lower()
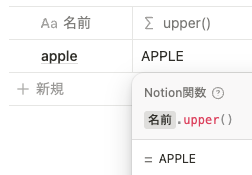
upper() は指定した文字列を全て大文字に、 lower() は指定した文字列を全て小文字に変換します。ひらがなや漢字などは大文字や小文字がないので、指定しても変化はありません。
let()・lets()
記事の冒頭でも述べましたが、関数 2.0 では let() ・ lets() を使用することで関数内で変数を使用することができます。 let() は以下のように使用します。
let(変数名, 変数, 変数を使った式) 例えば以下の例では、 tax という文字を変数名として設定し、 tax に 1.1 という数字を代入します。つまり tax=1.1 となります。そして最後の prop(”価格”) * tax は、 prop(”価格”) * 1.1 という計算式になります。
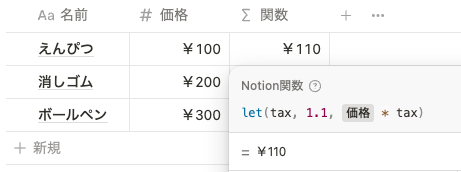
let(tax, 1.1, prop("価格") * tax) 最後の prop(”価格”) * tax の式の部分は、通常の関数と同じように if() などを使用することが可能です。
上記のようなシンプルな内容の場合は let() を使う必要はありませんが、例えば以下のように複雑な場合や、 tax が計算式の中に何度も出てくる場合は、 let() を使って変数を使用した方が関数が読みやすくなったり、後日 tax を変更したいという場合でも 1箇所のみ変更すればいいので、メンテが楽になります。
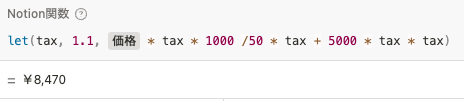
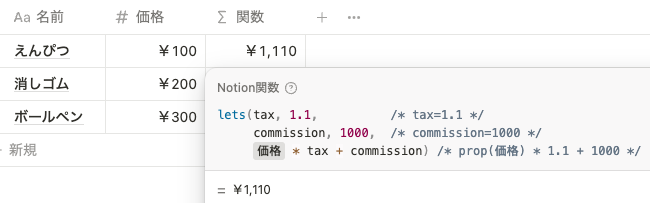
さらに lets() を使えば、変数を複数使用することができます。 lets() は以下のように使用します。設定する変数はいくつでも問題ありません。
lets(変数名1, 変数名1にセットする変数, 変数名2, 変数名2にセットする変数, ..., 変数を使った関数) 例えば、 tax=1.1 , commission=1000 という変数をセットしたい場合は以下のように記述します。
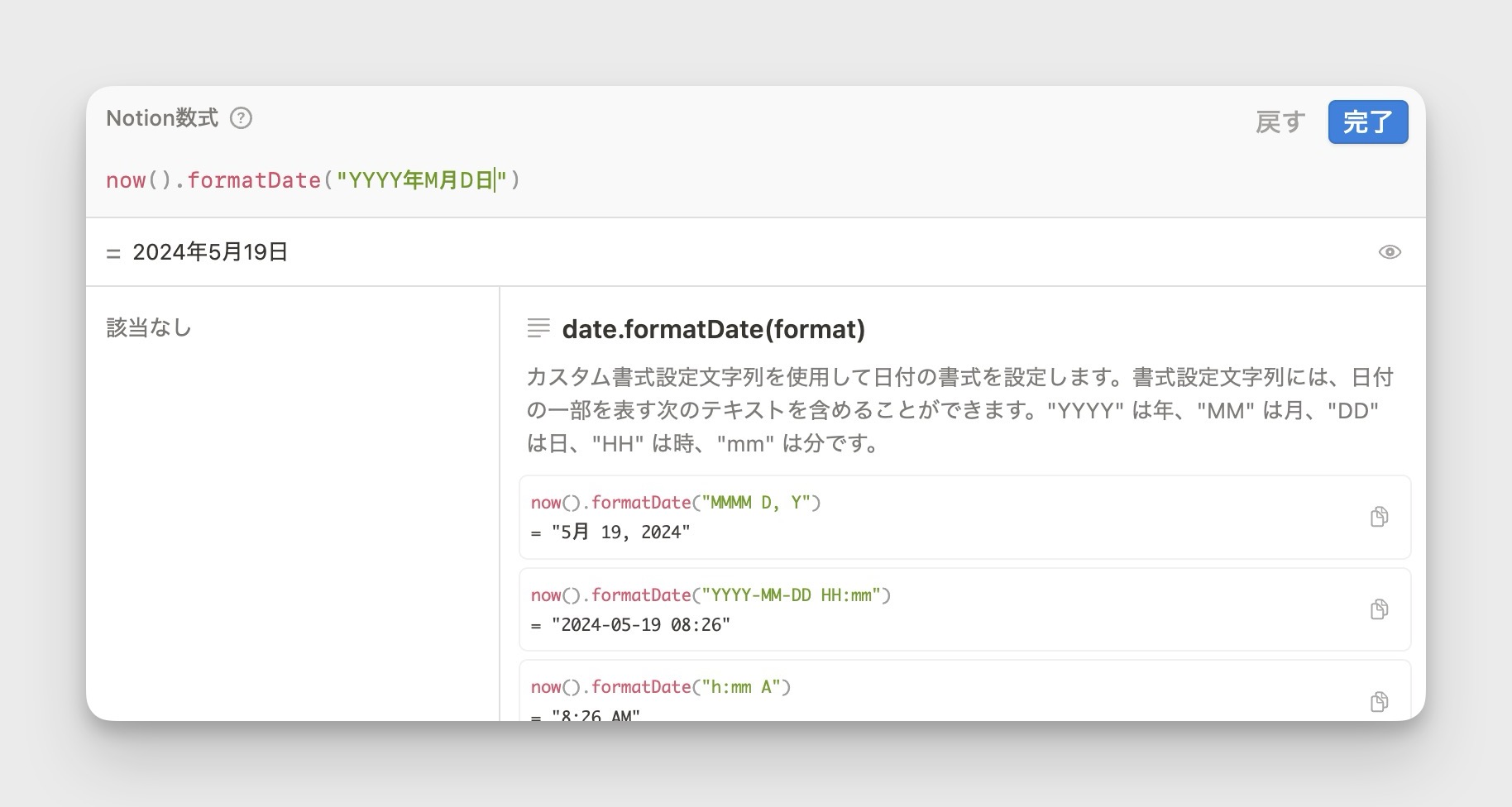
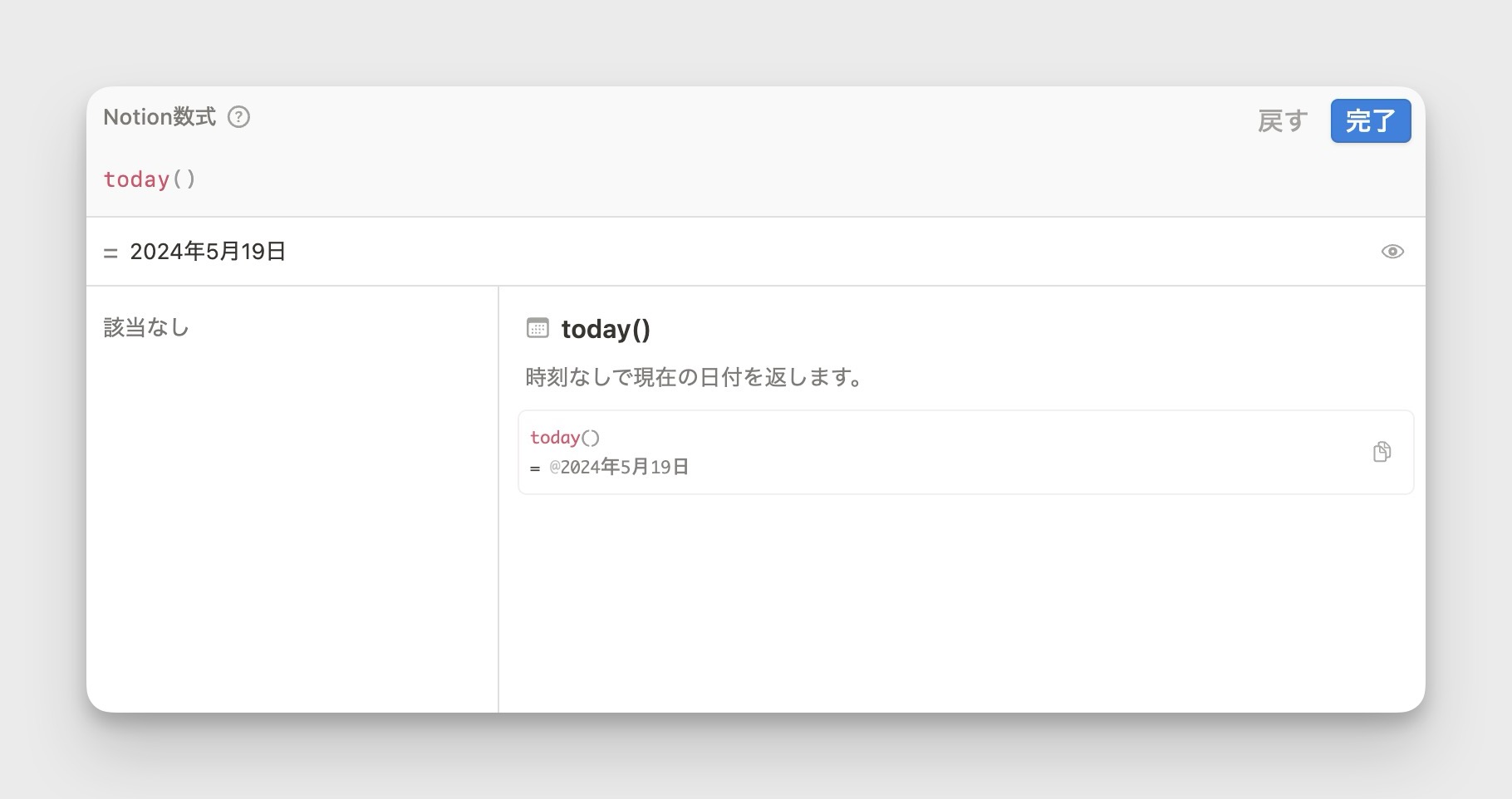
today() 2024年3月アップデート
従来は、日付のみを取り出したい now() 関数にフォーマットをかけ、日付データを取り出す必要がありましたが、today() 関数を使うことで日付データのみを出力できるようになりました。
3. リスト(配列)とは
リスト(配列)関連の新しく追加された関数について解説する前に、まずは 関数 2.0 で新しく追加されたリスト(配列)とは何かを解説します。
例えば、以下のようにカンマ区切りの数字 1, 2, 3 を [] で囲み、 [1, 2, 3] と関数に記述します。すると出力は 1, 2, 3 となります。これがリストです。
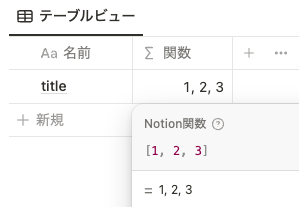
リストは一つの箱の中に複数の値が入っているイメージです。上記の場合は、一つの箱の中に 1, 2, 3 という三つの数字が入っています。リストには数字のみではなく、文字列や日付など、さまざまなプロパティを入れることができます。
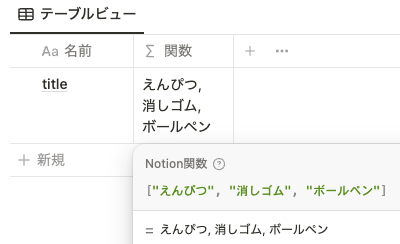
リストには値を直接記入するのではなく、プロパティを指定することもできます。
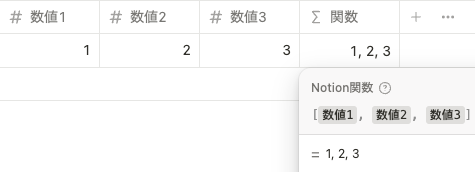
リストとなるプロパティ
関数でプロパティを取得する場合、リストとなるプロパティは以下の 4つです。
- マルチセレクト
- ユーザー
- リレーション
- ロールアップ
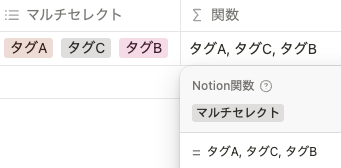
例えばマルチセレクトを関数で取得した場合は、以下のように タグA, タグC, タグB というリストとして取得されます。
新しく追加された関数(リスト関連)
ここからは、以下のようなシンプルなリスト [1 ,3, 1, 2] に対して、新しく追加されたリスト関連の関数の使い方を解説します。

sort()
リストを昇順、降順に並べ替えます。
▼ 昇順に並び替え

[1, 3, 1, 2].sort()▼ 降順に並び替え

[1, 3, 1, 2].sort(current * -1) 降順は少しややこしいですが、 sort(current * -1) のように引数で -1 をかければ降順に並び替えることができると覚えておきましょう。
reverse()
リストを逆順に並べ替えます。

[1, 3, 1, 2].reverse()sort()と組み合わせると、降順に並び替えることができます。

[1, 3, 1, 2].sort().reverse()first()
リスト内の最初の値を取り出します。
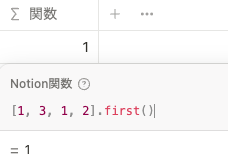
[1, 3, 1, 2].first()last()
リスト内の最後の値を取り出します。
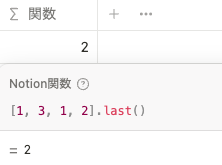
[1, 3, 1, 2].last()at()
リスト内の指定した位置の値を取り出します。注意点として、リストの先頭は 0 番目です。 at(0) の場合は最初の 1 が出力されます。
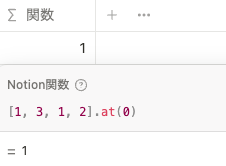
[1, 3, 1, 2].at(0)unique()
リスト内の一意の値のリストを返します。

[1, 3, 1, 2].unique()filter()
条件が true であるリスト内の値を返します。例えば、 [1, 3, 1, 2] のリストの中から 2 以上の数値のみを取り出したい場合、以下のように関数を記述します。
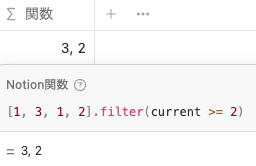
[1, 3, 1, 2].filter(current >= 2) current にはリスト内に入っているそれぞれの値が順番に入ります。上記の例の場合、以下のように処理されます。
-
1 >= 2はfalse -
3 >= 2はtrue -
1 >= 2はfalse -
2 >= 2はtrue
よって、 true である [3, 2] が出力。
また、 current の他に index も使用することができます。 index はリスト内の値の番号です。例えば、以下のようにfilter(index >= 2)と指定すると、リスト内の2番目以降(0番目から数えて)の値が出力されます。
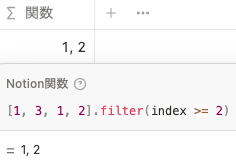
[1, 3, 1, 2].filter(index >= 2)find()
条件が true を返すリスト内の最初の値を返します。 filter() と似ていますが、 filter() は条件に当てはまる値を全て出力するのに対して、 find() は最初に条件を満たした値を一つだけ返します。
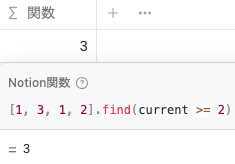
[1, 3, 1, 2].find(current >= 2)findIndex()
条件が true と評価されたリスト内の最初の項目のインデックスを返します。 find() では最初に条件を満たした値を一つ返しますが、 findIndex() ではインデックス(何番目か)を返します。例えば以下の場合、最初に current >= 2 を満たすのは 3 なので、インデックスは 1 です。
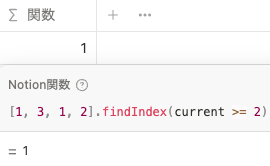
[1, 3, 1, 2].findIndex(current >= 2)map()
リスト内のすべての項目に対して map の () 内の式(条件)の結果を格納したリストを返します。例えば [1, 3, 1, 2].map(current * 2) という関数の場合、以下のような順番で処理されます。
-
1 * 2 = 2の結果の2を新しいリストに格納。今のリストは[2] -
3 * 2 = 6の結果の6を1.の手順のリストに追加で格納。今のリストは[2, 6] -
1 * 2 = 2の結果の2を2.の手順のリストに追加で格納。今のリストは[2, 6, 2] -
2 * 2 = 4の結果の4を3.の手順のリストに追加で格納。今のリストは[2, 6, 2, 4] - 作成された
[2,6,2,4]のリストが出力される。

[1, 3, 1, 2].map(current * 2)every()
リスト 内のすべての項目が指定された条件を満たす場合は true を返し、そうでない場合は false を返します。 条件を判定するという点では filter() と同じですが、 filter() の場合は条件を満たした値をリストとして返すのに対し、 every() はすべての値が条件を満たしているかどうかを判定し、真偽値( ture か false )を返します。
例えば、 current >= 1 が条件の場合は、リスト内のすべての値が current >= 1 を満たすので、 true を返します。
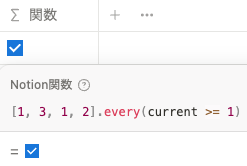
[1, 3, 1, 2].every(current >= 1) current >= 2 が条件の場合は、リスト内の値が1の場合に current >= 2 を満たさないので、 false を返します。
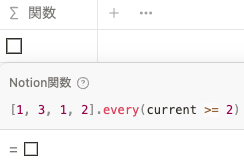
[1, 3, 1, 2].every(current >= 2)some()
リスト 内のいずれかの項目が指定された条件を満たす場合は true を返し、そうでない場合は false を返します。 every() と似ていますが、 every() は「すべての値が条件を満たしているか」を判定するのに対し、some()は「ひとつでも条件を満たしているか」を判定し、真偽値( ture か false )を返します。
例えば、 current >= 3 が条件の場合は、リスト内の 3 が current >= 3 を満たすので、 true を返します。
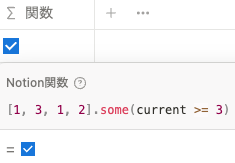
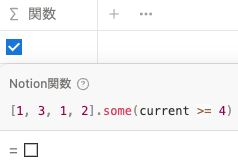
[1, 3, 1, 2].some(current >= 3) current >= 4 が条件の場合は、リスト内の値がひとつも current >= 4 を満たさないので、 false を返します。
[1, 3, 1, 2].some(current >= 4)flat()
リストのリストを単一のリストに平坦化します。例えば、リストの中にリストが入っている場合(二重リスト: [[1, 3, 1, 2],[5, 6, 7]] )、flat()を使うことで単一のリスト( [1, 3, 1, 2 , 5, 6, 7] )に変換されます。

[[1, 3, 1, 2],[5, 6, 7]].flat()join()
リストの値を指定した文字列で結合して出力します。
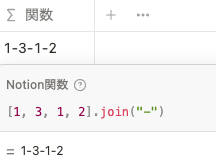
[1, 3, 1, 2].join("-")slice()
指定された開始インデックス(含む)から終了インデックス(省略可能、含まない)までの値を切り出し、リストを返します。例えば以下の例の場合、1 番目のインデックス(0番目から数えて)の値である 3 (含む)から、3番目のインデックスの値である 2 (含まない)の一つ前である 1 をリストに格納し返します。つまり、 [3, 1] を出力します。

[1, 3, 1, 2].slice(1, 3)その他のリストに関する関数
上記に紹介した関数以外にも、リストに関する関数はいくつもあります。中には今まですでにあった関数で、リストにも使えるというものもあるので注意してください。ここでは、残りの「リストに関する関数」について簡単に紹介します。
-
sum():リストの値の合計値を返します。 -
max():リストの値の中から最大値を返します。 -
min():リストの値の中から最小値を返します。 -
length():今までと同様、文字列に適用した場合は文字数を返しますが、リストに適用した場合はリストに含まれる値の個数を返します。 -
concat():複数のリストをひとつに結合します。 -
includes():リストに指定された値が含まれている場合はtrueを返し、そうでない場合はfalseを返します。 -
split():文字列を指定の区切り文字や条件で分割し、リストに格納します。 -
match():文字列から指定の正規表現に一致したものすべてをリストとして返します。
以下は2024年3月のアップデートで追加されました
-
mean():リストの平均値を返します。 -
median():リストの中央値を返します。
4. 関数 2.0(Formula 2.0)の注意点
関数 2.0 のアップデートにより、いくつか注意点があります。
関数は自動で書き換えられている
関数 2.0 への移行に伴い、一部の関数は自動で書き換えられています。特に修正はせずとも今まで通り関数は動くように設定されていますが、もし関数をメンテすることがあるならば、書き方が大きく変わっている場合があるので注意してください。
関数名は同じで機能が変更された関数
いくつかの関数は名称が変わっていないのに機能が変わっているという場合があります。
-
month()は今までは0から11を返していましたが、関数 2.0 では1(1月)から12(12月)を返します。日本人にとってはわかりやすくなりました。ただし、この変更に合わせて自動で関数が書き換えられている場合、month(date)はmonth(date) - 1に変換されているので注意してください。 -
day()は今までは0(日曜日)から6(土曜日)までの数値を返していましたが、Formulas 2.0 では1(月曜日)から7(日曜日)を返します。ただし、この変更に合わせて自動で関数が書き換えられている場合、day(date)はday(date) % 7に変換されているので注意してください。 -
slice()は今まで文字列の切り出しに使われていましたが、リストの切り出しに使われるようになりました。文字列の切り出しには新しくsubstring()が使用されます。substring()は今までのslice()の使い方と同じです。 -
concat()は今まで文字列の結合に使われていましたが、関数 2.0 ではリストの結合に使われます。文字列の結合は結合する文字列の間に+を記載することで結合できるようになりました。
名称が変更された関数
以下の関数は機能に変更はありませんが、名称が変更しました。
-
start(date)→dateStart(date) -
end(date)→dateEnd(date)
削除された関数
以下の関数は削除されましたが、代わりに演算子が使えるようになりました。
-
larger→> -
largerEq→>= -
smaller→< -
smallerEq→<=
5. 関数 2.0(Formula 2.0)のユースケース
ここからは 関数 2.0 で実現できるようになったいくつかのユースケースを紹介します。
テキストやリンクを見やすくする
style() や link() を使用することで、テキストやリンクを見やすくすることができます。
6. 【Notion】関数2.0(Formulas 2.0)の参考ペー ジ
Notion 公式アンバサダーの hkob さんが作成されているページがとても参考になります。関数で困りごとがある場合やより詳しく知りたい場合は一度見てみてください。
7. おわりに
この記事では、Notion の新しい関数機能「Formulas 2.0」について詳しく解説しました。Formulas 2.0 を使えば、今までには実現できなかったより便利な Notion の使い方を実現できるかもしれません。この記事で紹介した内容やユースケースを活用して、ぜひ一度 Formulas 2.0 をご自身で使ってみてください。